
Ever wondered if you can look closer at the pictures in a PDF file? Maybe you need to find out what text is inside an image or figure out more about its details. You’re not alone.
Many people have files filled with images that they wish they could analyze and understand better without the hassle of converting them into another format first.
Analyzing images within PDFs isn’t just possible; it’s actually becoming easier thanks to advancements in technology and tools designed specifically for this purpose.
This blog will guide you through different methods to explore the details held by images in any PDF document, from using special software to handy tips that make the process simpler.
Methods for Analyzing Images in PDF Files

Finding out what’s in the pictures inside a PDF file seems tricky, right? Well, it’s actually easier than you think. We’ve got some smart ways to pull it off without breaking a sweat.
From cool tools that grab text from images to clever tricks for spotting details, there’s more than one way to get the job done.
PDF library extraction
PDF library extraction is a handy tool for pulling images from PDF files. Libraries like PyMuPDF make this job easy. You just need to use the getImageList() method. This method gives you a list of all image objects in a PDF.
Then, with just a few lines of code, you can grab these images. So, if you’re working on analyzing images in PDFs, using a library like this saves time.
This method is popular among those who deal with lots of documents and data. It’s because it lets them get to the images they need quickly. Whether it’s for data parsing or information retrieval, extracting images this way is efficient.
Using PopAi
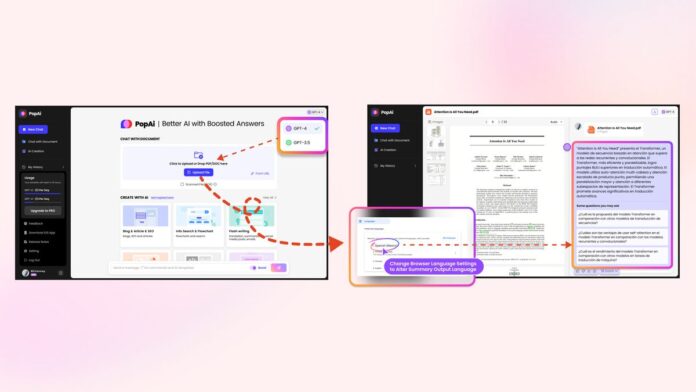
PopAi.pro is a game-changer for anyone looking to get more from their PDF files. With its advanced features, you can upload your document and let the AI tool do the heavy lifting. The magic begins as it reads through your PDF.
It’s not just any ordinary pdf tool; this ai pdf reader brings your documents to life by allowing you to interact with them like never before. Imagine chatting with your PDFs, asking questions, analyzing images using OCR, and getting answers right away.
The integration of a search engine makes finding information within documents easier than ever. This means less time spent flipping through pages and more time understanding the content.
Plus, PopAi isn’t limited to text analysis alone; it excels in image analysis too. By simply uploading your file, this platform transforms how we interact with digital documents, saving precious time and making information retrieval almost effortless.
Microsoft OneNote

Moving from PopAi to another powerful tool, Microsoft OneNote steps in with its OCR function. This feature is a game-changer for anyone looking to pull text from images or PDF files.
The Optical Character Recognition (OCR) technology in OneNote allows users to extract text easily. It’s perfect for scanned documents where you need to grab text for note-taking or sharing info quickly.
Whether you’re dealing with a single image or multiple pages in a PDF, the software recognizes the text and images within seconds.
You can then copy this extracted text into your notes, making it super handy for research and collaboration without losing time typing out long excerpts manually.
Tips for Analyzing Images in PDF Files

Getting the most from images in PDF files is all about knowing the right tricks to make them pop.
Highlight and copy method
To analyze images in any PDF file, the highlight and copy method is quite simple. First, select an area of an image you want to look at more closely. Then, right-click on that selected area.
From the options that appear, choose “Copy Image.” This action copies the image so you can paste it into another document or image editor for further analysis. It’s a straightforward way to pull visual data from PDF documents without needing special tools.
Copying visuals this way helps with extracting data from PDF images quickly. Whether you’re studying a graph or pulling out an important photo, this method makes it easy to move images from your PDF to where they can be examined more closely.
No need for complicated processes—just select, copy, and paste!
Quality check of embedded fonts and images
Making sure all fonts are in your PDF helps it look right on any screen. Acrobat Pro’s Preflight tool can spot font issues quickly. It checks if every font is there so your document shows up correctly everywhere.
For pictures, Adobe Acrobat Pro squeezes them into smaller sizes without losing their sharpness. This balance keeps files light but clear.
Next, find out if your PDF has all its fonts by using Adobe Acrobat or Reader. Just open the file and go to the File menu for a quick check. This step makes sure that text looks smooth and readable across different devices before moving on to searching with image OCR functions.
Searching using image OCR function
After checking the quality of images and fonts, we move on to how you can find text within those images. Image OCR function makes this task easy. This technology turns pictures in PDF files into text that you can search.
Think about a scanned document turned into a PDF file. Normally, you can’t search for words in it because the computer sees it as an image, not text.
But with OCR, the game changes. It reads the text in these pictures and converts them into searchable words. Now, searching through long documents is quick because the computer can see and find all the words, thanks to OCR technology.
Adobe Acrobat uses this tech to let users turn scanned documents into PDFs that are easy to search through instantly.
Conclusion
So, you have learned how to analyze images in PDF files. There are many tools that make it easy and doable. We’ve shared some tips aimed for simplicity in extracting useful info from visual data.
Why not try out these methods on your next PDF? They might save you time and open new ways of understanding documents. Let’s get started with analyzing those images!




")
