
Machine learning is a rapidly growing field that has revolutionized the way we approach complex data analysis tasks. The field encompasses a wide range of techniques and algorithms, each designed to tackle specific types of problems.
Two of the most common types of algorithms used in machine learning are regression and clustering. In this article, we’ll explore the key differences between these two types of algorithms and provide an overview of some of the most popular techniques used in each.
Regression Algorithms
Regression algorithms are used to predict a continuous output variable based on one or more input variables. These algorithms are used in a wide range of applications, from predicting stock prices to estimating the age of a person based on their height and weight. The basic idea behind regression is to find the relationship between the input variables and the output variable.
Linear Regression
Linear regression is one of the simplest and most commonly used regression algorithms. It involves finding the line that best fits the data points in a scatter plot. The line can then be used to predict the value of the output variable for any given input value.
Logistic Regression
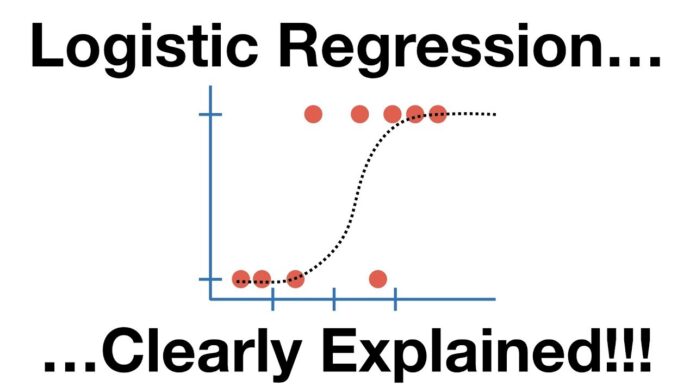
Logistic regression is a type of regression that is used to predict the probability of an event occurring. It is commonly used in binary classification tasks, where the goal is to predict whether a particular event will occur or not. Logistic regression models are trained on labeled data and are used to make predictions on new, unlabeled data.
Clustering Algorithms
Clustering algorithms are used to group similar data points together based on their characteristics. These algorithms are commonly used in a wide range of applications, from market segmentation to image recognition. The basic idea behind clustering is to find groups of data points that are similar to each other and different from other groups.
K-Means Clustering
K-means clustering is one of the most commonly used clustering algorithms. It involves finding the centroid of a cluster of data points and then grouping together all the points that are closest to that centroid. The algorithm iteratively refines the centroids until it finds the best grouping of data points.
Hierarchical Clustering
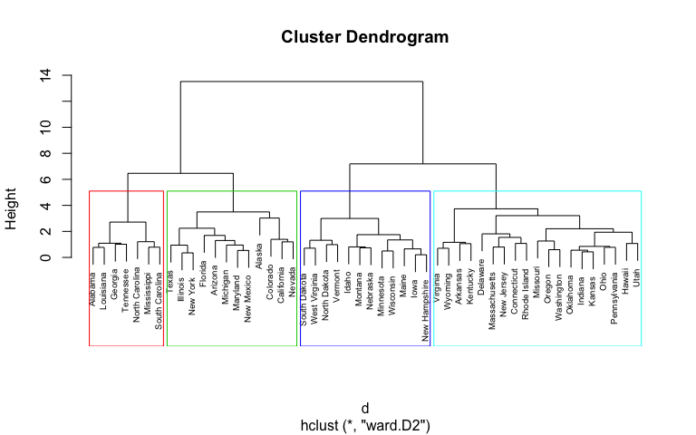
Hierarchical clustering is a type of clustering that is used to create a hierarchy of groups. The algorithm starts by treating each data point as a separate cluster and then iteratively merges the two closest clusters until all the data points belong to a single cluster. The result is a hierarchical structure that can be visualized as a tree diagram.
Conclusion
Machine learning algorithms are incredibly powerful tools that can be used to solve a wide range of complex problems. Regression algorithms are used to predict continuous output variables based on input variables, while clustering algorithms are used to group similar data points together.
By understanding the differences between these two types of algorithms and the techniques used within each, you can choose the best algorithm for your specific data analysis task.




")
