
Today, Data Analytics and Machine Learning are instrumental for accomplishing business goals. However, organizations require well-curated Data Pipelines and Data Warehouses that can support their analytical framework. This is where Data Engineering comes into play. This domain involves building a functional Data Infrastructure to ensure that data is present in a secure and analysis-ready form for Data Analysts and Data Scientists. Data Engineering is also responsible to streamline data flow while preserving Data Integrity.
Deriving valuable insights from data is a critical aspect for businesses. This is only possible if companies have powerful Data Infrastructures in place. To develop such Infrastructures and maintain their functioning, businesses employ Data Engineers. This blog introduces Data Engineering and explains its key components. Read along to understand more about the role of a Data Engineer and the world of Data Engineering!
Introduction to Data Engineering
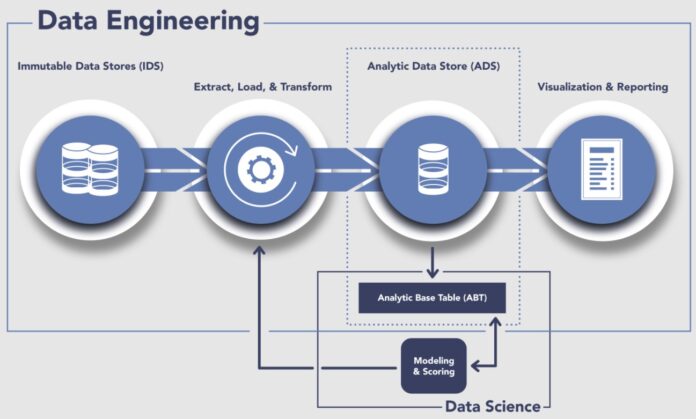
Data Engineering is a collection of operations that intends to build mechanisms and interfaces to allow seamless access and flow of data. Data Engineering encompasses all the processes required to build and maintain Data Infrastructures. It also marks a shift from the conventional ETL setup to a comprehensive system of tools working together to process and manage data. It also focuses on creating new tools that can scale to match the ever-increasing volumes of data.
Data Engineering is an umbrella term that includes major processes such as Data Warehousing, Data Modeling, Data Crunching, and Data Mining. This derivative of Data Science empowers companies to indulge in the applications of Data Analysis and Data Collection.
Components of Data Engineering
The process of managing Data Flows for an organization is a tough nut to crack. You, as a Data Engineer will be tasked with building and maintaining the major components required to facilitate Data Processing. To excel at this role, you need to first understand what components are important to this field and how they contribute to Data Management.
The Data Engineering domain consists of the following major components:
1) ETL Pipeline
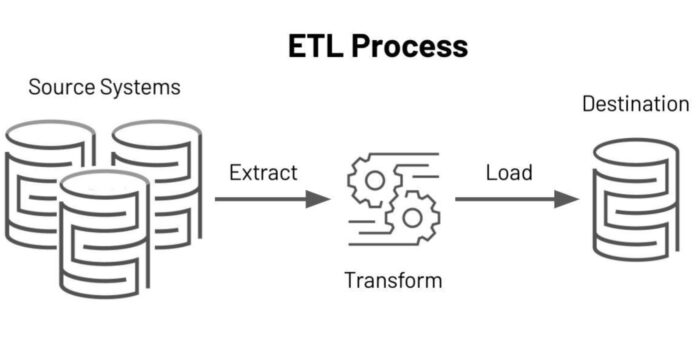
Companies have data incoming from diverse Data Sources. Managing such data can be tricky at times and to extract insights of real value from this data, you would need to deploy a Data Pipeline. Now, a common question that arises is, What is Data Pipeline?
A Data Pipeline can be defined as a set of tools & processes that can accomplish the following Data Processing tasks:
• Extract: Assemble raw data from multiple Data Sources that are essential to your company.
• Transform: Cleanse, Modify and Enrich this data into the analysis-ready form.
• Load: Transfer the modified data to a Data Lake or Data Warehouse that will act as the single source of truth.
These ETL or ELT processes require a complex set of tools and skilled professionals. Moreover, you may face unexpected bottlenecks while manually performing the ETL processes. The code can throw errors, parts of data can go missing, noise & inconsistent data can delay loading, and so on. Businesses often simplify these processes by using an automated Data Pipeline tool. This way, you can ensure end-to-end reliability and security for your ETL tasks.
A Data Pipeline is responsible for the consistent and effortless migration of your data. However, building an in-house Data Pipeline still needs regular maintenance and your Data Engineers will have to manually perform the Data Mapping process. A simpler alternative is to use a 3rd-party tool that can automate your entire ETL process. Hevo Data is one such option. It provides a No-code Data Pipeline that not only automates your Data Mapping tasks but also provides you with the option to extract data from 100+ sources in real-time.
2) Data Warehouses
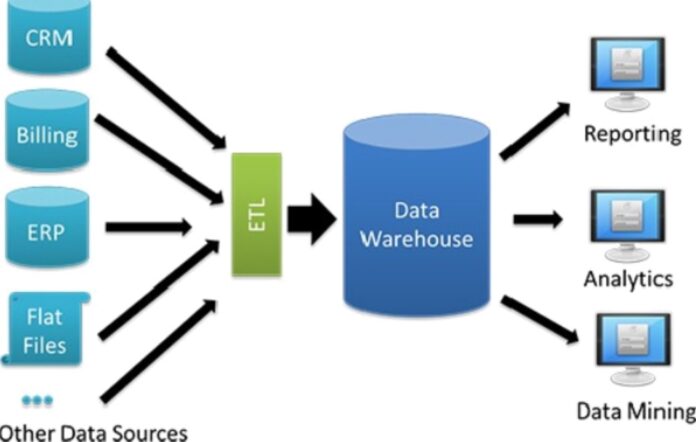
A Data Warehouse is a spacious repository where you can aggregate vast sets of data from multiple sources like APIs, Databases, Files, Social Media Platforms, etc. It acts as the destination for the ETL (Extract Load Transform) Pipeline process and allows you to prepare your data for analysis. Data Warehouses facilitate Business Reports, Data Analysis, Ad-hoc Queries, and other major operations on data. The following points highlight the importance of Data Warehouses in the current business scenario:
Databases can only manage your daily business transactions. This is because Databases are designed to hold data in a normalized form whereas high-speed query processing requires denormalized datasets. Therefore, to perform a deep analysis of your historical records you need the facility of a Data Warehouse.
A business consumes data from data sources in various formats, and club it to generate valuable insights. Modern Data Warehouses allow you to enter both Structured & Unstructured Data and convert it into an analysis-ready form. This way it simplifies a Data Analyst’s job, allowing for modification from a single interface that will result in deriving analytics, visualizations, and statistical insights.
Data Warehouse also serves as a commonplace for companies to create Metadata. It also has provisions for hiding sensitive information regarding the identities of your users & partners. This way, you can make the Warehouse data available to everyone without risking a privacy breach.
The advent of Cloud-based Data Warehouses has further solidified the importance of these Data Storage tools. Snowflake, Google BigQuery, Amazon Redshift, etc., are some popular names that allow businesses to store and process petabytes of data seamlessly using Cloud Technology.
3) Data Marts
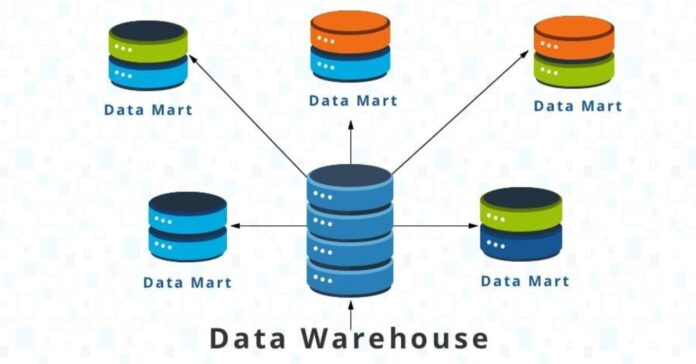
A Data Mart represents a small storage that hosts information regarding the working of a specific domain in an organization. For example, your company can build a Data Mart for its Marketing Department or its Finance Department.
Data Marts serve a specific audience and never store the complete data of the organization.
They help in turning raw data into actionable insights and promote the work of individual business units. They accomplish this by offering customized summaries and queries for their specific domain leaders. Data Marts safeguard your Data Analysts from searching through an entire company’s data and provide them direct access to information from their domain. Since a Data Mart caters to a single business line, it provides faster query processing than a Data Warehouse.
Depending on their content and purpose, Data Marts are of the following 3 types:
• Dependent Data Marts: They are created on top of an Enterprise Data Warehouse and contain a subset of its data. In case the central Data Warehouse crashes, these Data Marts also stop working.
• Independent Data Marts: These are standalone entities that can act as miniature Data Warehouses. They function by extracting information from multiple external and internal Data Sources. These Data Marts require a high level of technical expertise and customized queries to function.
• Hybrid Data Marts: This system involves a set of data Marts some of which are independent while others rely on a Data Warehouse. The Hybrid model aggregates information from Data Warehouses and other Operational Units of the business.
4) OLAP
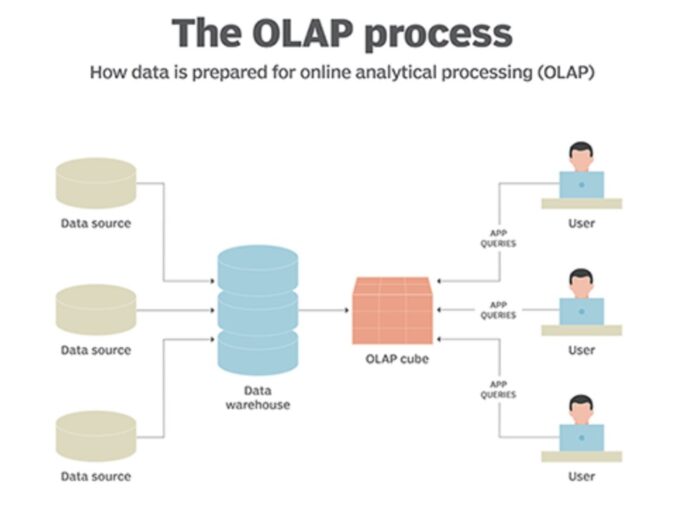
OLAP (Online Analytical Processing) refers to the analytical aspect of Data Engineering. It’s opposite to the OLTP (Online Transactional Processing) mechanism which allows you to interact with databases and manage transactional queries. OLAP is designed for analyzing massive amounts of data from new perspectives. For instance, you can Drill Down/Roll Up the data if you wish to modify the hierarchy level (details) of data. You can also perform Data Slicing to segment out a specific Dataset or Dice it to generate a new OLAP Cube. The output of the OLAP mechanism provides patterns from your data and facilitates a wide range of reports.
OLAP utilizes a multidimensional structure called OLAP Cubes for storing Data. This structure accounts for dimensional processing and analysis of huge data volumes. For instance, a Sales Report can include dimensions like Product, Sales Amount, Region, Month, and so on. To implement OLAP dimensionally, you need to custom-built OLAP Cubes for every particular type of report or query. This overhead is justified, as they allow advanced Multidimensional Data Analysis in a hassle-free manner.
Role of a Data Engineer
Data Engineers are responsible to assemble, process, clean, validate, and transform data to match the business requirements. They are frequently assigned the task of developing novel algorithms to enhance data accessibility inside an organization. Their responsibilities extend well beyond the creation and maintenance of Data Processing infrastructure. Data Engineers must also have the know-how of Data Applications and Pipelines.
Data Engineers regularly evaluate and update the performance of Data Pipelines. Their major work entails managing information flow and data access rather than performing in-depth Data Analysis. The jobs of Data Analysts and other Data Professionals depend largely on Data Engineers’ efforts.
Data Engineers must be well-versed in Big Data technologies. They should also be familiar with NoSQL Solutions, HIVE, CouchDB, and should possess experience in data structuring & processing technologies. Furthermore, they must have a command over programming languages like Python, SQL, and tools like Apache Spark, and Apache Hadoop.
Conclusion
This blog introduced Data Engineering and discussed the various components that are essential to this field. It also briefed about the role of a Data Engineer in today’s data-driven business world. Data Engineering is a necessity for businesses from all verticals and promises great career opportunities. By working as a Data Engineer, you will need to collect and transfer data from multiple sources to a Data Warehouse before the other teams can act on it. Developing an in-house solution for this data transfer can be complex and expensive.




")
